Vertical Scaling Postgres with Zero-downtime
在這篇文章中我們會聊到
- 什麼是 Vertical Scaling 與 Horizontal Scaling
- 什麼是 Streaming Replication 與 Logical Replication
- 最小停機時間的 Vertical Scaling 策略
- Zero-downtime 的 Vertical Scaling 策略
什麼是 Vertical Scaling 與 Horizontal Scaling
為避免誤會以下說明都是用機器來舉例,但 Vertical Scaling 與 Horizontal Scaling 的擴展方式泛指所有與機器或 Pod 等相關的 Scaling 方法,並不是單純指 Database 的機器
Vertical Scaling (Scaling Up)
透過新增機器的 CPU/Memory 或其他硬體資源的方式來提升機器的資源。舉例來說新增 CPU(4 Cores -> 8 Cores)。
Horizontal Scaling (Scaling Out)
透過新增機器數量的方式來讓原本繁重的工作負擔分散到更多的機器身上,常見的 AWS ECS 與 Kuberentes 的 Auto Scaling 都是採用這種方式。舉例來說 10 個 Pods 承受不住目前的流量那就開 20 個 Pods。
當 Database 的請求量或工作負載量已經超越資料庫本身機器能負荷的上限時,就需要進行 Scaling。至於該採取哪種 Scaling 方式,我們會需要搭配當下的機器狀況或產品特性來判斷。
- 情況 1: 大量 Query 的流量超過機器所能承受時,我們會需要多開幾台 Replica Database。透過多台 Read Database 來分擔 Query 的流量,已達成降低原本 Replica 機器 CPU loading 太重的問題。
- 情況 2: 流量中包含大量的 Mutation 的請求時,Master Database 的 CPU 或 Disk 跟不上請求速度,導致 CPU wait 或 Replication Lag 上升。這種情況會選擇直接提升機器的 CPU 或 IOPS。
什麼是 Streaming Replication 與 Logical Replication
Streaming Replication
Streaming Replication 是基於 WAL 的一種物理複製的方式,Streaming Replication 最常用在 Master-Slave 的架構中,也是我們常見的 AWS RDS 與 GCP Cloud SQL 的 Read Replica 的實現方式。簡單來說就是從 Master Node 複製 WAL 到 Slave Node 來達成 replication 的目的。由於是物理複製,所以會造成 Slave Node 只能 Read Only 的限制,但也因為是物理複製,幾乎沒有資料遺失的風險。

優點
- 具備高可用性,除了 Master 與 Slave 同時掛了以外,幾乎沒有資料遺失的風險。
- 由於 Slave 是 Master 的複製品,所以不會有因為格式不同而需要更動 Master 上 Schema 的狀況。
缺點
- Slave 只能 Read Only
- 無法支援 Postgres 不同版本的 streaming replication
Logical Replication
Logical Replication 是一種邏輯複製的方式用來複製資料或資料異動,邏輯複製聽起來很抽象,可以想像成就是把 Source Database 端的資料異動透過 Insert/Update/Delete 等的 SQL 命令從發送端送到接收端去執行。Logical Replication 是透過 Publish 與 Subscribe 的模式,所以也能同時支援多個 subscriber,並且發送的最小單位是 Transation。

優點
- 可以選擇指定的 table 就好,不需要整個 Database 做 replication
- 可以跨版本的做 replication,當然就要處理 data type 不相容與 Data Schame Conflict 的問題 (可以參考pglogical)
- 不需要 Master-Slave 的架構,兩台 Master 也是 Logical Replication 常見的搭配
- publisher/subscriber 底層的 pg_wal directory 不需要一樣
缺點
- 由於 postgres 可以跨版本或 Schema 不一定要相同,需要處理大量的 Conflict,不然會有掉資料的風險
- 不支援 DDL (Create/Alter/Drop 等) 相關的處理
- 當發生衝突時,replication 就會中止,直到衝突被解決
最小停機時間的 Vertical Scaling 策略
前面前情提要那麼多,重點終於要來了。以下舉例的前提都是一台 Master 搭配一台 Replica。
先說目的,我們要提升一倍的 Master 與 Replica 的 CPU (舉例 8 Cores -> 16 Cores)。以 GCP 來說,如果從 Conosle UI 或 gcloud CLI 上直接調整機器的 CPU/Memory 的話,大約要 5 分鐘的 downtime 時間。我們可以透過一些簡單的策略來降低這些停機時間的影響。
切流量的方式有很多,可以透過 pgbouncer 或 DNS 等方式,這邊就不細說
以下步驟為 Replica zero-downtime 策略的步驟:
- 目前狀況是我們會有一台 Master A(8 cores)與一台 Replica A(8 cores)
- 建立一台 Replica B(16 cores),大約要 15~20 分鐘的建立時間
- 等 Replica B 準備完成後,將流量導到 Replica B (Replica 升級完成)
- 這時 Replica A 已經沒有任何流量了,升級 Replica A (8 Cores -> 16 Cores)
- 升級 Master A (8 Cores -> 16 Cores),Mutation 停機時間約 5 分鐘
- Master A 升級完成後刪除 Replica A (Master 升級完成)
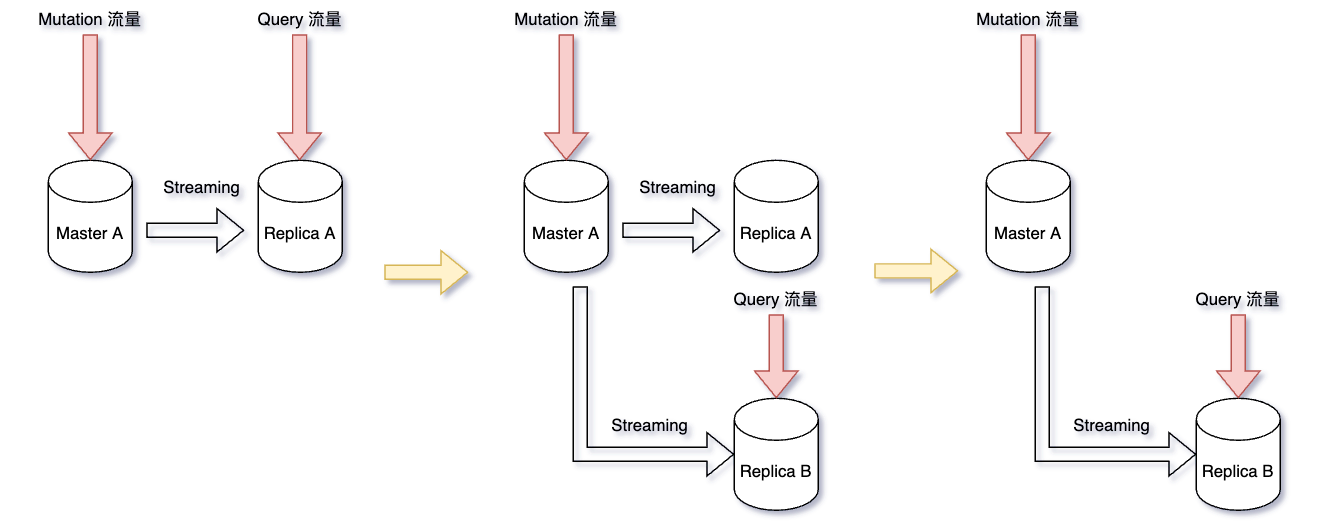
這邊其實我們多做了 Replica A 的升級然後又把 Replica A 刪掉的動作,目的是當步驟 5 的 Master 升級失敗後,我們能夠把 Replica A 直接 Promote 成新的 Master,以降低風險。
那可以直接在步驟 5 就 Promote Replica A 成為新的 Master,然後再把流量切過去?
由於這邊的場景都是透過 Streaming Replication 來進行資料同步,所以當 Replica A 要 Promote 成為新的 Master 時,Master A 與 Replica A 的 Streaming Replication 的動作就會被中止,所以在 Replica A -> 新 Master -> Master DB 切流量這段時間的資料異動將會流失,所以不建議直接透過 Promote 的方式來處理。
Zero-downtime 的 Vertical Scaling 策略
延續上面的策略,我們透過新增 Logical Replication 的機制就能達到 Zero-downtime 的目的。
Zero-downtime 的步驟:
- 目前狀況是我們會有一台 Master A(8 cores)與一台 Replica A(8 cores)
- 建立一台 Replica B(16 cores),大約要 15~20 分鐘的建立時間
- 等 Replica B 準備完成後,將 Replica B Promte 成 Master B
- Master A 設定 Logcial Replication 到 Master B
- 從 Master B 新增一台 Replica B (16 cores)
- 將 Read 流量從 Replica A -> 切到 Replica B (Replica 升級完成)
- 將 Mutation 流量從 Master A -> 切到 Master B (Master 升級完成)
- 刪除 Master A 與 Replica A
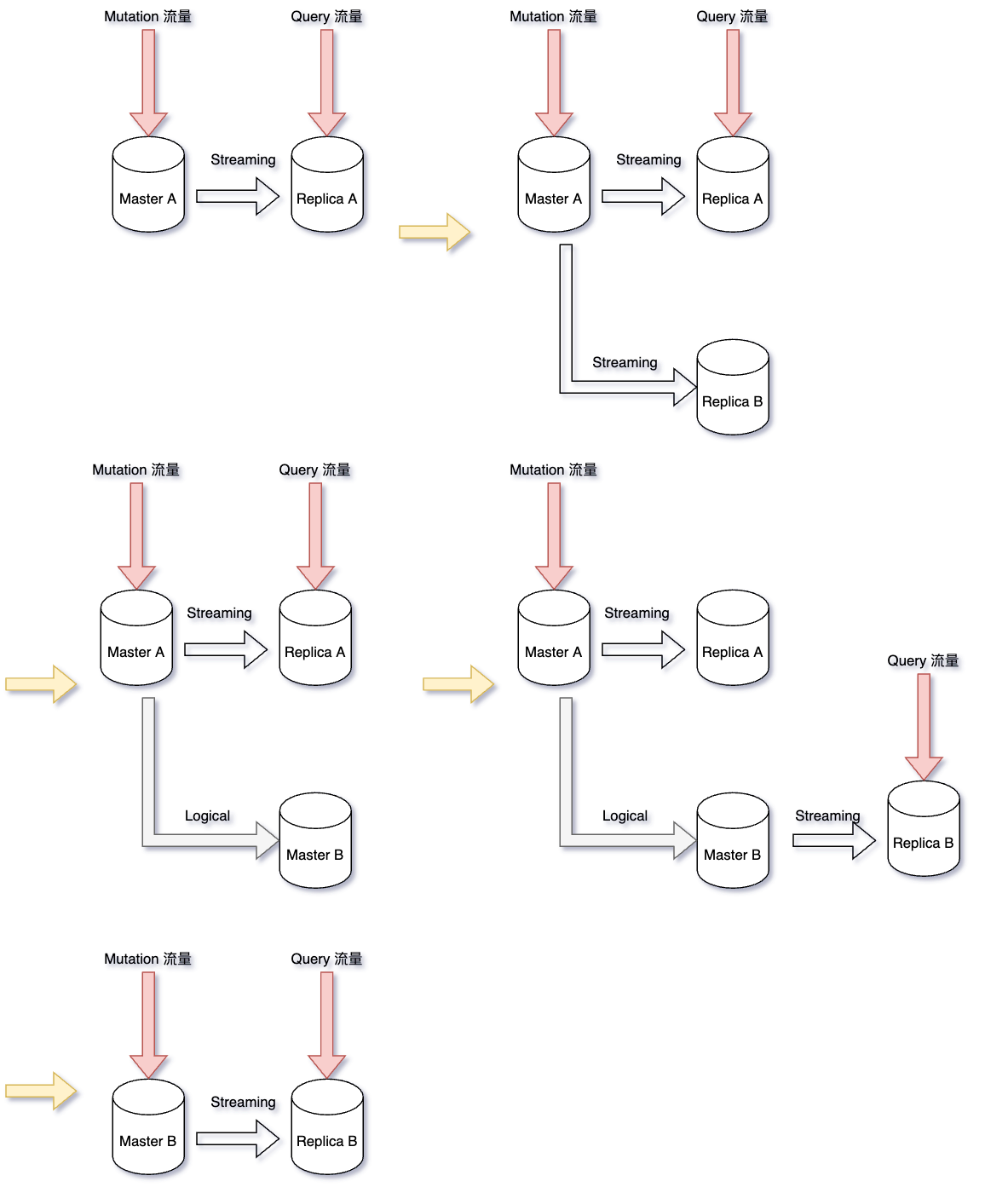
這個範例只是升級 CPU/Memory,而且兩個 Master 之間的 Schema 也都一致,並不會產生 Logical Replication 的 Data Conflict 的問題,算是比較好處理的場景,如果又加上跨版本的 Postgres 要考慮的情況就會更多了。
結論
雖然我這邊都是拿 Vertical Scaling 來舉例,但這些策略並非只能用在提升 CPU 或 Memory 的用途,只要把步驟稍微改一下也能將這些策略應用於 Postgres Upgrade/Migration 等需要較長時間的升級。
Zero-downtime 的策略雖然能夠達到不停機的目的,但所需要處理的設定也遠比有 downtime 還要多很多,團隊最終決定在夜深人靜的時候直接讓 Master downtime 5 分鐘 XD。希望下次有機會把這些策略應用在 Postgre Upgrade 中並完成 Zero-downtime 的成就。