Database Index
前言
此文章的目的並非讓大家對於 Btree 有深度了解,而是使用簡單的方式解釋 Database Index 的基本原理,使得在設計 Index 的時候有正確的方向。
介紹
當我們發現資料庫 Query 速度越來越慢,且已經漸漸地影響到使用者體驗的時候,那就是優化資料庫的最佳時機,而最典型的方法就是加 index,但是在設計上如果不理解 index 的原理而隨便亂加的話,反而會造成整體資料庫效率降低!!
目前多數的 RDBMS 的 index 都是由 Btree 的方法實作,所以講 Database index 之前,必須先簡單了解一下 Btree 的基本特性。
Btree
這是 Btree 的基本樣貌:
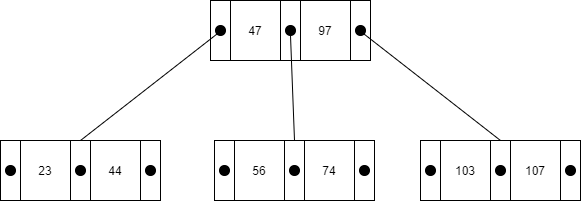
Btree 共有幾種特性:
- 有別於一般二元樹,每個 node 都能擁有多個 Key
- 一個 node 可以擁有 K+1 個支線(K = Key 的數量)
- Key 數值必在兩個 Parent 的 Key 範圍內(如圖上的 56/74 都在 47 及 99 內)
- Btree 為平衡樹且每個葉節點深度必定相同
接著我們來看一下 Search 速度上的差異,圖上的例子共有 23/44/47 等八個數字,若我們用 For-loop 的方式尋找,最差情況是 O(n)
若我們從 Btree 的方式搜尋,則最差情況是最深階層數,故為 O(log n)
Database index
其實在使用資料庫的同時,我們已經不知不覺中使用了大量的 index,而這個 index 就是每個 Table 的 Primary Key,接下來我們就用 PK 來解釋 Database 的搜尋方式
首先我們先建立簡單的 Table
create table test(
id integer primary key,
num integer,
content varchar(40)
);
找出目前 test table 內的 index,可以看出 Primary Key 本身就會被建立成 index
eric_db=# select * from pg_indexes where tablename = 'test';
schemaname | tablename | indexname | tablespace | indexdef
public | test | test_pkey | | CREATE UNIQUE INDEX test_pkey ON public.test USING btree (id)
接著我們來討論 index 與 Btree 之間的關係
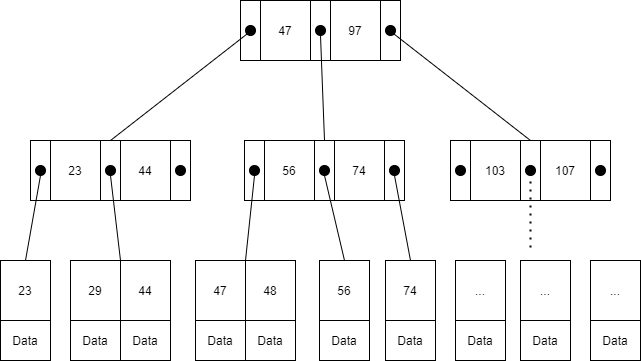
圖中所有的 Key 都是 test 中的 id(PK),而在葉節點的部分才會帶該筆 id 的資料內容。
Query
select * from test where id = 29;
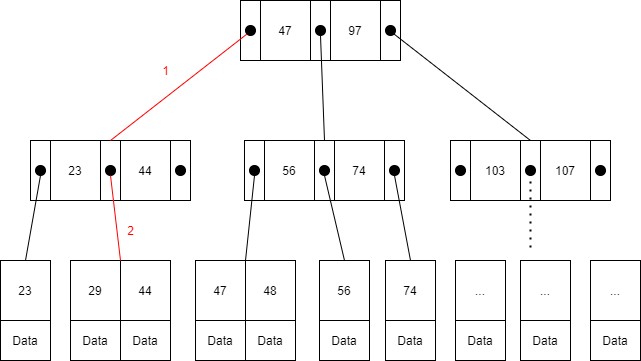
當我們下 Query 時,Database 找出 id 為 29 的方式如圖上所示,且與 Btree 的走訪方法相同,這邊我就不重複解釋。比較不同的是資料僅存在於葉節點,走訪的過程即便是遇到 Key 相同只要不在葉節點就無法取得資料。
那假設我們是找 num = 29 的時候也是照著 Btree 的方法?
答案是否定的,只要沒設 index,Database 就會用 full scan 的方式去搜尋。
原理
每當我們建立 index 時,Database 都會幫我們建立一個 index table 去維護這個 Btree,所以 index 越多則 index table 當然也越來越多,所需要的空間需求也會隨之增加。
當我們建立 Primary Key 以外的 index 時,基本上原理都是相同的,差別只在於非 PK 的 Btree 葉節點的資料內容為 PK。
接著上面的範例,我們設了 num 為 index,然後找出 num = 29,Database 動作如下
- 透過 num 的 btree 找出 id
- 再由 id 的 btree 找出整個 row 的內容
我的硬碟就是大,那我每個欄位都設 index 來加速好了
上面有提到 Database 會幫我們維護所有的 index btree,若 index 太多會造成新增或刪除資料的時候負擔太大,同時維護多個 Btree(包括這些 index table 的讀寫動作)所造成的負擔都會使你的系統效能變差。
實驗
隨機建立 100 萬份資料
create table test(
id integer primary key,
num integer,
content varchar(40)
);
create index test_num_index on test(num);
insert into test SELECT generate_series(1,1000000) as id, (random()*(10^3))::integer, (random()*(10^3))::VARCHAR(40);
若沒有 postgres 的環境的話,可以用 docker-compose 來玩,這邊是我實驗的環境
version: "3.3"
services:
postgres:
image: postgres:latest
container_name: eric_db
ports:
- 5432:5432
environment:
POSTGRES_DB: eric_db
POSTGRES_USER: eric
POSTGRES_PASSWORD: eric
volumes:
- ./init.sql:/docker-entrypoint-initdb.d/init.sql
explain 是 postgres 提供出來查詢 sql command 的成本,我們就用此方法來實驗
eric_db=# explain select * from test where content = '29';
QUERY PLAN
Gather (cost=1000.00..13561.43 rows=1 width=26)
Workers Planned: 2
-> Parallel Seq Scan on test (cost=0.00..12561.33 rows=1 width=26)
Filter: ((content)::text = '29'::text)
(4 rows)
eric_db=# explain select * from test where id = 29;
QUERY PLAN
Index Scan using test_pkey on test (cost=0.42..8.44 rows=1 width=26)
Index Cond: (id = 29)
(2 rows)
若未使用 index 的情況下成本為 13561.43,這邊 Postgres 已經幫我們使用了並行處裡,否則成本會更高。反觀使用 index 的總成本只需要 8.44
這邊我就不解釋此成本的計算方式,簡單理解成數值越高成本越大即可,有興趣者可前往 postgres 的 document。
結論
index 是非常典型的以空間換取時間的例子,但也不是 index 越多越好,而是必須透過實際情況來決定哪些 column 該設定 index,都沒用到的 column 設定 index 也是很浪費的。